Chenglin Yang
Research Scientist
I am currently a Research Scientist at ByteDance Seed. During my graduate studies, I have interned at Google DeepMind, Google Research, and Adobe.
I received my Ph.D. in Computer Sciense, advised by Bloomberg Distinguished Professor Alan Yuille from Johns Hopkins University.
I am currently working on the pretraining of LLMs.
My Chinese name is 杨程麟.
Email: chenglin.yangw at gmail dot com
Interests
- Pretraining of LLMs
- Quantization
- Reinforcement Learning
- Knowledge Distillation
Selected Publications

Publications
(2023).
IG Captioner: Information Gain Captioners are Strong Zero-shot Classifiers.
In ECCV24.
(2022).
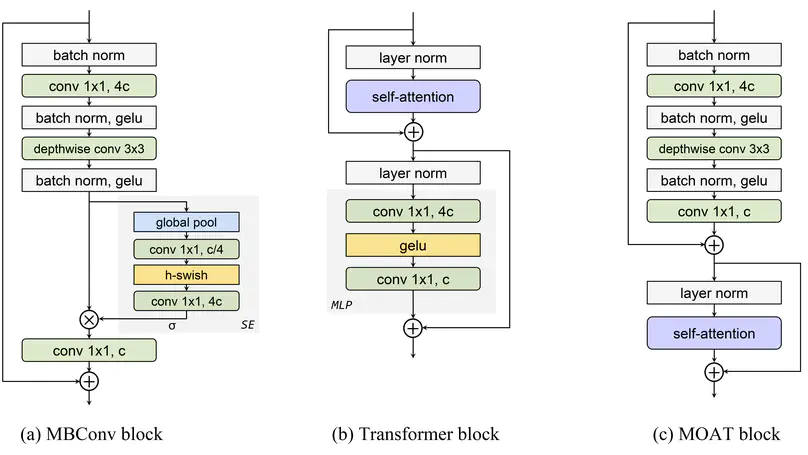
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models.
In ICLR23.
(2022).
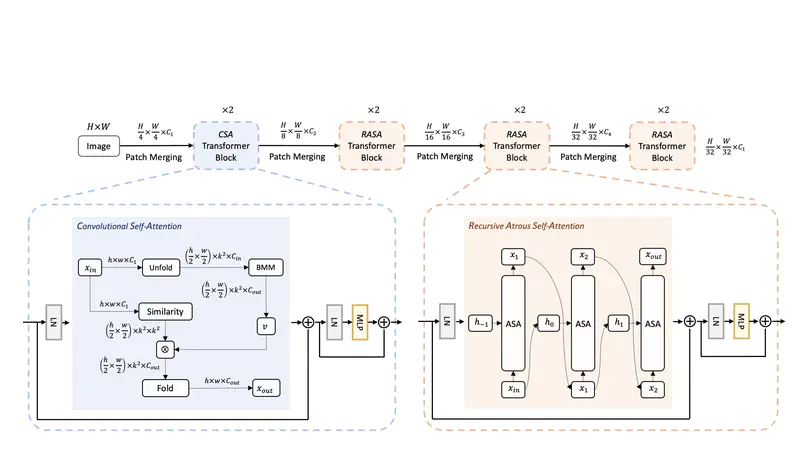
Lite Vision Transformer with Enhanced Self-Attention.
In CVPR22.
(2020).
PatchAttack: A Black-box Texture-based Attack with Reinforcement Learning.
In ECCV20.
(2019).
Snapshot Distillation: Teacher-Student Optimization in One Generation.
In CVPR19.